バギングとブースティングは、アンサンブル学習の代表的な手法です。
バギングの方が、ブースティングよりも素早く計算ができることが多いです。
ブースティングの方が、バギングよりも精度の高いモデルが得られることが多いです。
アンサンブル学習は、弱学習器(決定木など、簡単に構成できるが、精度はそこまで高くないモデル)をたくさん集めることで、精度の高い分類や予測を行う手法です。このページでは、アンサンブル学習の代表的な手法である、バギングとブースティングについて解説します。
バギングとは
例えば、弱学習器を決定木(分類木)にした場合のバギングは、図のようになります。
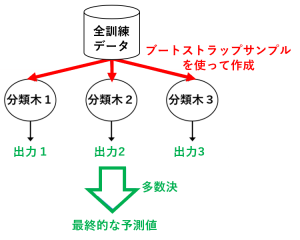
ブートストラップとは、復元抽出によって、各弱学習器のデータセットを作成する手法のことです。例えば、もとのデータが $(d_1,d_2,d_3,d_4,d_5)$ の5つからなるとき、
・1番目の決定木の作成には $S_1=(d_1,d_2,d_4,d_4)$ を使い
・2番目の決定木の作成には $S_2=(d_1,d_3,d_4,d_5)$ を使う
というような感じです。
バギングの代表的な例として、ランダムフォレストが挙げられます。
参考:ランダムフォレストの概要を大雑把に解説
※「多数決」の部分は回帰問題の場合は「平均値」などの代表値を取る計算に変わります。
ブースティングとの違い
ブースティングでは、バギングのように弱学習器を独立に作るのではなく、1つずつ順番に弱学習器を構成していきます。その際、$k$ 個目に作った弱学習器をもとに(弱点を補うように)$k+1$ 個目の弱学習器を構成します。
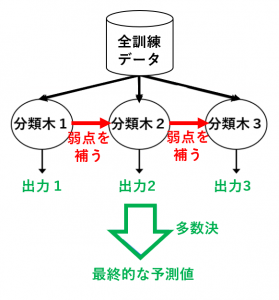
例えば、弱学習器を決定木(分類木)にした場合のバギングは、図のようになります。
ブースティングの具体例としては、AdaBoost、XGBoost、LightGBM、CatBoost などがあります。
参考:ブースティングとアダブースト(AdaBoost)について詳しく解説
バギングとブースティングの比較
バギングは、弱学習器を独立に作成するため、計算を並列に行うことができます。そのため、計算時間をかけずに、比較的精度の高いモデルを得ることができます。
一方、ブースティングは、今まで作った弱学習器の弱点を補うように次の弱学習器を作るので、全体として、より精度の高いモデルを得ることができます。
つまり、
・とにかく素早くそれなりのモデルが欲しい場合は、ランダムフォレストなどのバギングの手法を使う
・とにかく精度の高いモデルが欲しい場合は、LightGBMなどのブースティングの手法を使う
というのがおすすめです。
次回は スタッキング(stacked generalization)の発想とやり方 を解説します。