スタッキング(Stacking / Stacked Generalization)は、複数のモデルを段階的に組み合わせて精度を上げる、アンサンブル学習の代表的手法です。特に Kaggle などの機械学習コンペでは、最終的な精度を底上げするための必須テクニックとして頻繁に使われています。
スタッキングとは何か?その核心
スタッキングとは、1段目(ベースモデル)の予測結果を新たな特徴量として利用し、2段目(メタモデル)で最終予測を行うアンサンブル学習手法を指します。
一般的なバギング・ブースティングと異なり、スタッキングでは「モデルの出力」そのものを特徴量として再学習します。
そのため、ロジスティック回帰・LightGBM・ニューラルネットなど、性質の異なるモデルを組み合わせ、より広い表現力を持つ予測モデルを作ることができます。
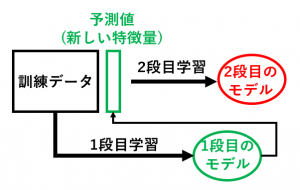
1段目のモデルは複数でもよいため、A・B・C…と多様なアルゴリズムを組み合わせることで、総合力の高いモデルを構築できます。
なぜスタッキングで精度が上がるのか?
異なるモデルは、それぞれ得意・不得意があり、誤差の種類も異なります。
スタッキングでは、これら複数のモデルの予測値を入力として扱うため、モデル同士の弱点を相互補完できるというメリットがあります。
特に、モデルが複雑なほど単純な平均よりもスタッキングが強力になり、Kaggle 上位勢が最終提出で使うことも多いです。
スタッキングの具体的な手順(わかりやすい例)
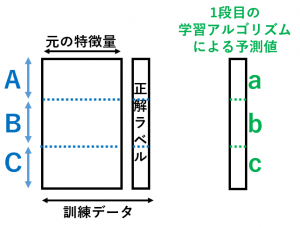
【スタッキングによる学習の手順】
1. 訓練データを $N$ 個に分割(以下では $N=3$ として説明)
2. 1段目の学習アルゴリズムで「Out-of-Fold 予測値」を作る
・A+B で学習 → C に対する予測値 c
・B+C で学習 → A に対する予測値 a
・C+A で学習 → B に対する予測値 b
3. 「元の特徴量+1段目の予測値」を入力として、2段目の学習アルゴリズムでメタモデルを構築
【スタッキングによる推論の手順】
4. 全データで1段目のモデルを学習し、テストデータに対する予測値を作成
5. 「テストデータの元特徴量+1段目の予測値」を用いて、2段目モデルで最終予測を行う
スタッキングで最重要となるポイント
手順2で作成する予測値 a・b・c は、必ずそのデータを学習に使わない状態(Out-of-Fold)で作ります。
A の予測値を作る際に A の正解ラベルを学習に使ってしまうと、2段目のモデルでカンニング状態になり、過学習が発生します。
さらに、1段目のモデルを$M$ 個使う場合は、
・手順2(OOF 予測)
・手順4(テスト予測)
をすべてのモデルで実施し、2段目の特徴量が$M$ 個増えることになります。
どんな 1段目モデルを選べばよい?
スタッキングでは、できるだけ多様なモデルを組み合わせるのがコツです。
良い例:
・LightGBM + ニューラルネットワーク
・ランダムフォレスト + 線形モデル
・XGBoost + kNN + ロジスティック回帰
悪い例:
・XGBoost + LightGBM(性質が似ている)
→ 精度向上幅が小さくなりやすい
スタッキングの欠点と、代わりに使える手法
「そこまで複雑にしたくないが、複数モデルを活かしたい」ときは、以下の代替手法が有効です:
・複数モデルの単純平均
・精度に応じた重み付き平均
・AUC などの指標では順位の平均(rank average)
・同じアルゴリズムでも seed を変えて多様化(seed averaging)
これらは実装が軽く、適用しやすいので実務でもよく使われます。
スタッキングに関するFAQ
Q1. スタッキングとブレンディングの違いは?
A. ブレンディングは「Holdoutデータ(検証用データ)に対する予測のみ」を使って2段目モデルを作る手法で、スタッキングより簡単ですがデータ効率が劣ります。
Q2. 2段目のモデルは何を使うべき?
A. 一般的にはロジスティック回帰や線形モデルが安定します。
複雑なモデルを使うと過学習しやすいため注意が必要です。
Q3. 回帰でも分類でもスタッキングできる?
A. はい、どちらにも適用できます。OOF 予測値を作る考え方は変わりません。
Q4. 1段目のモデルは何個まで使うべき?
A. 多すぎると計算量が爆発するため、3〜6個程度が実務的には現実的です。
まとめ:スタッキングは「最終的な精度を引き上げる切り札」
スタッキングは複雑ですが、以下の利点があります:
・異なるモデルの長所を組み合わせられる
・単純平均よりも大きく精度改善することがある
・Kaggleでも実務でも非常に強力
「最後の数パーセントを上げたい」場面では、スタッキングは最優先で検討すべき手法です。
次回は 名義尺度、順序尺度、間隔尺度、比率尺度 を解説します。