代表的な分類モデル、および回帰モデルである決定木について。
分類木の例
下図のように、日々の温度と湿度のデータ、および、その日A君が暑いと感じたか暑くないと感じたかのデータが与えられた状況を考えてみます。
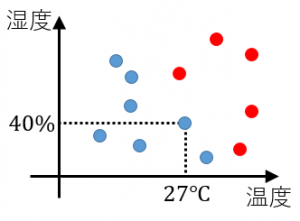
図の1つの点が1日を表します。赤い点はA君が暑いと感じた日、青い点は暑くないと感じた日を表します。例えば、温度が $27$ 度で湿度が $40$ %の日は暑くないと感じています。
このデータから、例えば、下図のような温度と湿度がどのようなときに暑いと感じるのか?を表現したツリーを作ることができます。
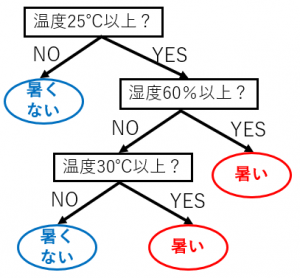
このように分類のルールをツリーで表現したものを分類木と言います。
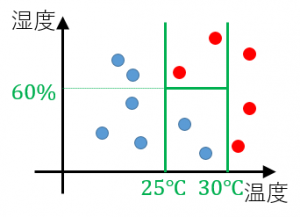
この分類木を、もとの入力データの図に境界線を追加して表現することもできます。もとのデータを縦と横に分割して、それぞれの長方形領域で暑いか暑くないかを定めるモデルです。
なお、この例は二値分類ですが、3つ以上のグループの分類問題にも有効なモデルです。
回帰木の例
下図のように、日々の温度と湿度のデータ、および、その日にA君が飲んだ水の量のデータが与えられた状況を考えてみます。
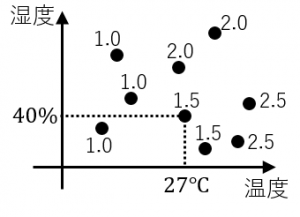
図の1つの点が1日を表します。数字は飲んだ水の量を表します。例えば、温度が $27$ 度で湿度が $40$ %の日には水を$1.5$ リットル飲んでいます。
このデータから、例えば、下図のような温度と湿度がどのようなときにどれくらいの水を飲むのか?を表現したツリーを作ることができます。
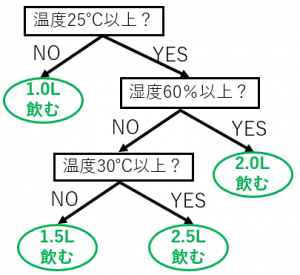
このように、ある数値(連続値)の推定のルールをツリーで表現したものを回帰木と言います。
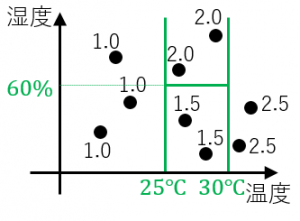
この回帰木を、もとの入力データの図に境界線を追加して表現することもできます。もとのデータを縦と横に分割して、それぞれの長方形領域で水を飲む量を定めるモデルです。
(このように単純な回帰木でデータを完全に説明できることは、まずありませんが。)
決定木とは
分類木と回帰木は似ていますね。分類木と回帰木のことを合わせて決定木と言います。
やりたいことが分類(分類モデルの作成)のときは、分類木を使い、やりたいことが数値の予測(回帰モデルの作成)なら回帰木を使います。
決定木は比較的単純なモデルですが、モデルをツリーで表現できるので、どの説明変数が目的変数にどのように効いているのかが視覚的に分かりやすいというメリットがあります。
決定木をどのように作るのか(決定木作成のアルゴリズム)は、例えば CART など、様々な方法が知られています。
※「決定木」は特定のアルゴリズムを表す用語ではありません。分類木という分類モデルと回帰木という回帰モデルを合わせたモデルの総称です。
次回は ランダムフォレストの概要を大雑把に解説 を解説します。